Value at Risk (VaR)#
import pandas as pd
import numpy as np
import datetime
import matplotlib.pyplot as plt
%matplotlib inline
plt.rcParams['figure.figsize'] = (10,5)
plt.rcParams['font.size'] = 13
plt.rcParams['legend.fontsize'] = 13
from matplotlib.ticker import (MultipleLocator,
FormatStrFormatter,
AutoMinorLocator)
from cmds.portfolio import *
from cmds.risk import *
LOADFILE = '../data/risk_etf_data.xlsx'
info = pd.read_excel(LOADFILE,sheet_name='descriptions').set_index('ticker')
rets = pd.read_excel(LOADFILE,sheet_name='total returns').set_index('Date')
prices = pd.read_excel(LOADFILE,sheet_name='prices').set_index('Date')
FREQ = 252
Definition#
The Value-at-Risk (VaR) is simply a quantile of the distribution.
The \(\tau\)-day, \(\quant\) quantile VaR of an asset or portfolio is defined as \(\pnlVaRqtau\) such that
where \(\pnl\) is the dollar amount of the pnl
and \(\port\) is the value of the portfolio.
This says that…
there is a probability of \(\quant\)
that over a horizon of \(\tau\) days
the portfolio PnL will be less than\(\pnlVaRqtau\).
Returns#
It is often useful to discuss the \(\VaR\) return, \(\rVaRqtau\):
Note that
Profits versus Losses,#
Our definitions above imply that \(\pnlVaRqtau\) and \(\rVaRqtau\) will be negative numbers (for all interesting cases.)
Be careful to note that the \(\VaR\) may be defined with respect to
Left tail of profit, \(\pnl\)
Right tail of losses, (a positive number,) \(\loss = -\pnl\)$
Below, the notation will focus on returns and PnL.
However, when discussing VaR, we will often focus on the absolute value.
This is a reason that some references will focus on losses, \(L\), to get a positive value for VaR.
Distribution#
If \(\pnl\) has a cumulative density function (cdf) that is
continuous
strictly increasing then we can simply write:
where \(\cdf_{\pnl}\) denotes the (unspecified) cdf of returns, and \(\cdf^{-1}_{\pnl}\) is its inverse.
Similarly, we have
Technical Note#
If the distribution of returns (profits) does not have such a cdf, then we need a more general definition,
Similarly for returns, \(\rVaRqtau\).
Normal Distribution#
\(\VaR\) will often be modeled using a normal distribution.
This may seem strange given the evidence we saw yesterday that returns are not normally distributed–especially for the tails!
Serious risk management would not rely on a normal distribution in most cases.
But the normal \(\VaR\) formulas are–if nothing else–an important way to quote and compare \(\VaR\).
Suppose that profits and returns are normally distributed. Focusing on returns,
where the subscript \(\tau\) is a reminder that the mean and variance depend on the return horizon, \(\tau\).
Normal Formula#
Then from the results above, we immediately have
where \(\zscore_\quant\) is the value (z-score) of the standard normal cdf associated with quantile \(q\). That is, if \(\cdfz\) denotes the standard normal cdf, then
Note that this formula for \(\rVaRqtau\) immediately gives us \(\pnlVaRqtau\), recalling that
Lognormal#
Suppose that prices are lognormal, so that log returns are normal with a one-period mean of \(\mu\) and one-period variance of \(\sigma^2\).
Then we have the following formula for the \(\tau\) horizon,
If we additionally assume
log returns are iid
log return mean, \(\mu\) is zero.
then we get the result that \(\rlog^{\VaR}\) scales with the square root of the horizon:
Punchline#
This formula is widely used as a convention, even though…
returns are not iid! (And typically the modeling within VaR will recognize that.)
mean is not zero
we typically use returns, not log returns!
Thus, for any \(\VaR\), (profits, returns, log returns,) you’ll typically see
\(\VaR\) compounding with the square root of the horizon.
Technical Point#
We could use log returns, but it would require a different formula for \(\VaR\) profits, and these would no longer be normally distributed.
Conditional Value-at-Risk (CVaR)#
Definition#
Conditional VaR (CVaR), also widely known as Expected Shortfall (ES) is the expected value conditional on being less than the \(\VaR\) threshold.
Normal Distribution#
Suppose we continue with the normal distribution of returns from above.
The \(\CVaR\) is the conditional expectation of a normal distribution, which gives us the following:
Technical Point#
We get the closed-form solution for \(\CVaR\) from an well-known result about the truncated normal distribution. That is to say, the conditional expectation of a normal distribution.
Consider a standard normal, \(\zscore\)
Let \(\pdfz\) denote the pdf of the standard normal.
It is well known that for any threshold, \(a\),
Sufficient Statistics of a Normal#
Note the similarity between the formulas for \(\VaR\) and \(\CVaR\) when assuming a normal distribution:
This is not a surprise.
The normal distribution is completely characterized by its mean and variance.
That is, these two parameters are sufficient statistics for a normal variable.
Any statistic of a normal distribution can be rewritten as a function of \(\mu\) and \(\sigma\).
Rescaled volatility#
Thus, \(\VaR\), \(\CVaR\), etc are all just rescalings of volatility if we are using a normal model.
In some sense, this is what normal \(\VaR\) is really about–having a scaled volatility.
Coherence#
Is \(\VaR\) a coherent risk measure?
No. In general, it is not subadditive.
Examples#
Payoffs#
Consider the payoff outcomes for \(\pnl_i\) and \(\pnl_j\) across 5 potential states of the world: $\(\pnl_i \in \begin{bmatrix}-2\\-1\\0\\1\\2\end{bmatrix}, \hspace{1cm} \pnl_j \in \begin{bmatrix}-1\\-2\\0\\1\\2\end{bmatrix}\)$
The states are ordered, such that in state \(s\), both securities deliver the payoff in row \(s\) of their respective arrays.
Consider a portfolio payoff that is the sum of the two: \(\pnl_p = \pnl_i + \pnl_j\).
What is $\(\pnl_i^{\VaR_{.2}}, \hspace{1cm}, \pnl_j^{\VaR_{.2}}, \hspace{1cm} \pnl_i^{\VaR_{.2}} + \pnl_j^{\VaR_{.2}}, \hspace{1cm} \pnl_p^{\VaR_{.2}}\)$
Example: Returns Not Subadditive#
Suppose there are 100 potential outcomes (“states”).
We have two assets, \(r_i\) and \(r_j\).
In almost every state, the return is simply $\(r_{s,i}=r_{s,j} = \frac{s-50}{100}\)$
The only exception is $\(r_{i,(5)} = -.45, r_{j,(5)} = -.46\$\)
Then for each return individually,
Yet for the equal-weighted portfolio, \(r_p = .5r_i + r_j\),
Issue#
The VaR is sensitive to the ordering around the specified quantile.
If two series do not share the timing of the returns around the \(\quant\) threshold may happen.
For instance, suppose we are looking at the worst-case scenario, and their worst and second-worst dates are swapped.
Data example#
We already saw this was the case with SPY and UPRO across 2017-2023!
Normal VaR#
Is Normal VaR coherent?
CVaR#
Is CVaR coherent?
For a normal distribution?
For the examples above?
Conditional Moments#
Whether using a normal model or something else, we want to allow \(\VaR\) to be dynamic across time. That is, we want the conditional \(\VaR\), utilizing info up to time \(t\).
For normal \(\VaR\) this means having a dynamic model of the volatility.
As mentioned earlier, we typically want conditional versions of any of our risk statistics, so we have broader reasons to want conditional volatility rather than unconditional volatility.
The mean#
It will be typical to ignore the mean in the following calculations.
Thus, the formulas calculate the second moment rather than the centered second moment.
Why do you think this convention is often used?#
Model for the mean#
And note, there is nothing wrong with including the estimated mean in the formulas below (and adjusting the degrees of freedom.)
If using a model for the mean, consider \(r\) in the formulas below as the residual after demeaning.
Notation for the volatility estimates#
Below, we use the notation that \(\sigma_t^2\) is estimated using data through \(t-1\) as an estimate of what variance will be the next period (\(t\)).
Expanding#
Rolling#
EWMA#
The exponential weighted moving average (EWMA) puts more weight on more recent data by setting a geometric decay parameter, \(\lambda\in [0, 1]\). (Typically \(\lambda\) will be in \((.9,1)\).
GARCH#
GARCH looks a lot like EWMA, but note that
the parameters do not need to sum to 1
it could be expanded to take lags of \(r\) or \(\sigma\), which would be a GARCH(2,1), GARCH(1,2), etc.
Evaluating VaR#
The Hit Test is a common way of backtesting a VaR methodology.
It checks historically what the daily VaR would have been, given the information known at that time. It compares this to the actual performance for the day.
If the VaR is working well, then the day-t loss should only exceed the day-\(t\) \(\pnl^{\VaR_{\quant,1}}\) with a probability of \(\quant.\)
But what if future market environment is very different than past environment with which fit test was run? Many VaR models looked okay before the 2007-2008 crisis hit!
import pandas as pd
import numpy as np
import datetime
import warnings
import matplotlib.pyplot as plt
%matplotlib inline
plt.rcParams['figure.figsize'] = (12,6)
plt.rcParams['font.size'] = 15
plt.rcParams['legend.fontsize'] = 13
from matplotlib.ticker import (MultipleLocator,
FormatStrFormatter,
AutoMinorLocator)
import sys
sys.path.insert(0,'../cmds')
from portfolio import *
from risk import *
LOADETF = '../data/risk_etf_data.xlsx'
px = pd.read_excel(LOADETF,sheet_name='prices').set_index('Date').dropna()
rets = px.pct_change().dropna()
FREQ = 252
WINDOW = 60
QUANTILE = .05
mu = 0
METHODS = ['empirical cdf','expanding vol','rolling vol']
sigma_expanding = rets.expanding(WINDOW).std()
sigma_rolling = rets.rolling(WINDOW).std()
sigma = pd.concat([None,sigma_expanding,sigma_rolling],axis=1,keys=METHODS)
from scipy.stats import norm
zscore = norm.ppf(QUANTILE)
VaRret = dict()
CVaRret = dict()
VaRret[METHODS[0]] = rets.expanding(WINDOW).quantile(QUANTILE)
CVaRret[METHODS[0]] = rets[rets<VaRret[METHODS[0]]].expanding().mean()
for method in METHODS[1:]:
VaRret[method] = mu + zscore * sigma[method]
CVaRret[method] = mu - norm.pdf(zscore)/QUANTILE * sigma[method]
VaRret = pd.concat(VaRret,axis=1)
CVaRret = pd.concat(CVaRret,axis=1)
fig, ax = plt.subplots(6,2,figsize=(12,20))
for i,tick in enumerate(rets.columns):
indax = [int(np.floor(i/2)),i%2]
VaRret.swaplevel(axis=1)[tick].plot(ax=ax[indax[0],indax[1]],title=f'{tick} VaR',
legend=indax[1]==1) # Only show legend on right subplots
plt.suptitle('Value at Risk (VaR) by Asset', y=1.02)
plt.tight_layout()
fig, ax = plt.subplots(6,2,figsize=(12,20))
for i,tick in enumerate(rets.columns):
indax = [int(np.floor(i/2)),i%2]
CVaRret.swaplevel(axis=1)[tick].plot(ax=ax[indax[0],indax[1]],title=f'{tick} CVaR',
legend=indax[1]==1) # Only show legend on right subplots
plt.suptitle('Conditional Value at Risk (CVaR) by Asset', y=1.02)
plt.tight_layout()
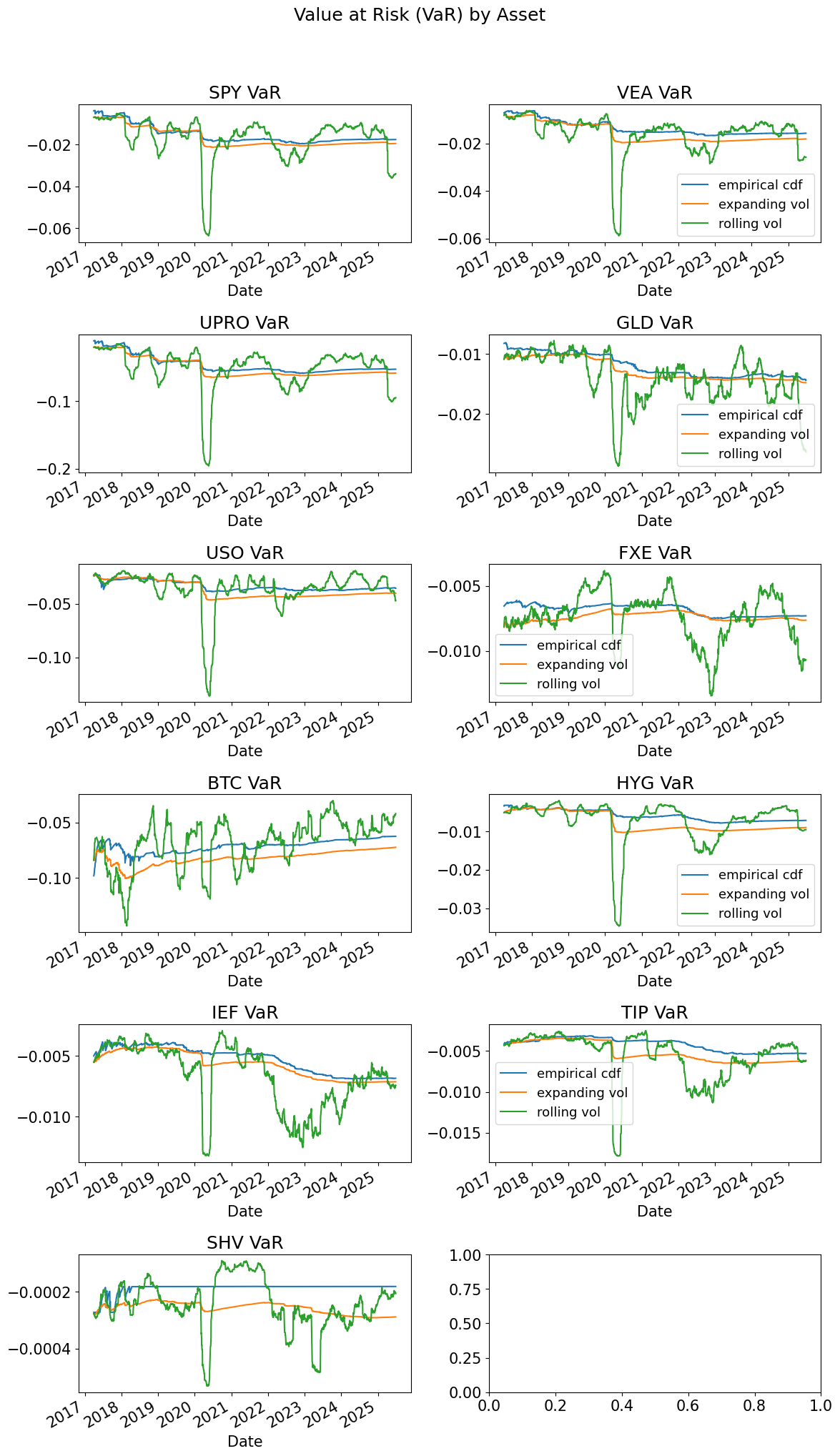
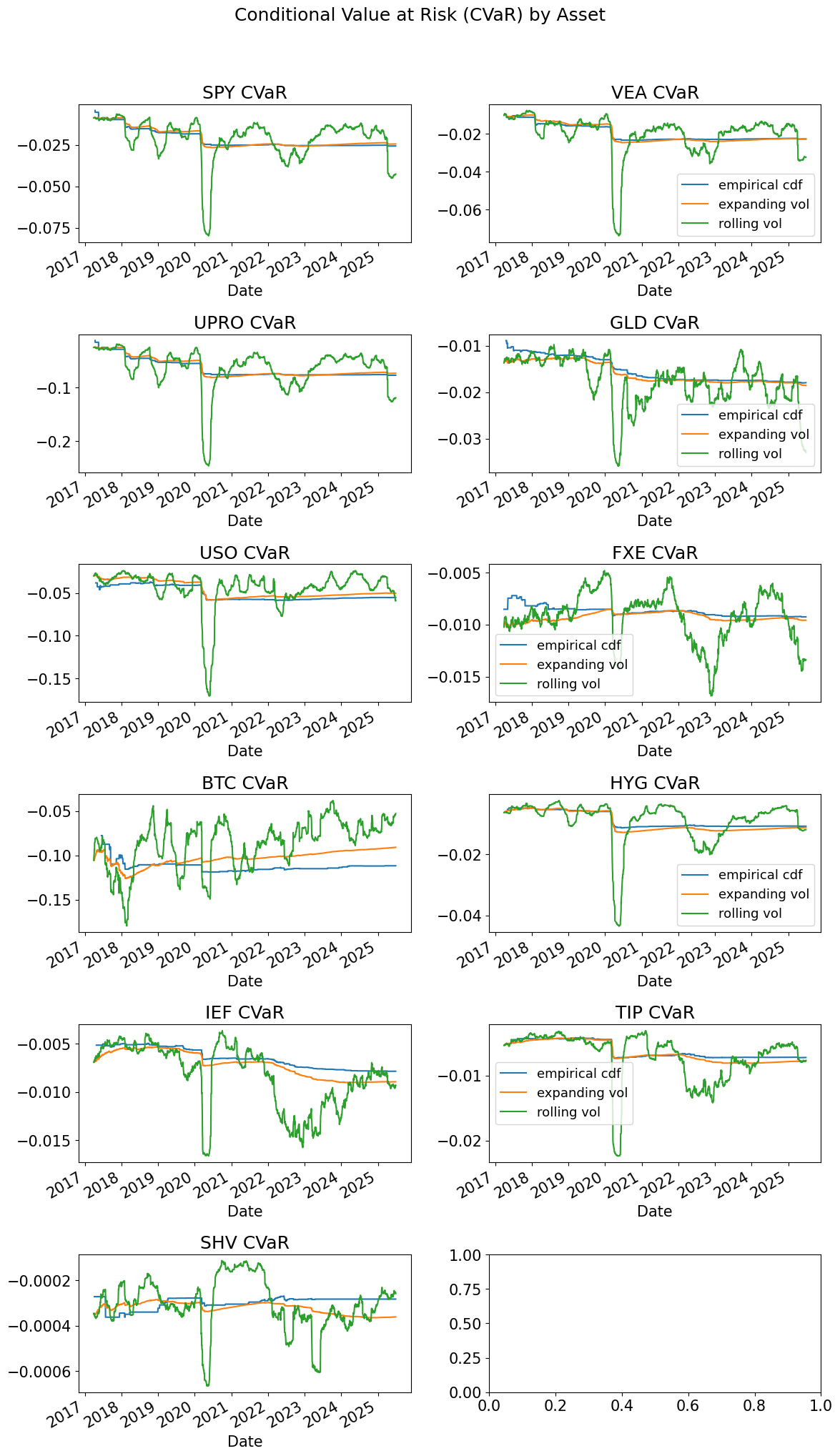
hits = dict()
for method in METHODS:
hits[method] = rets < VaRret[method].shift()
hits = pd.concat(hits,axis=1)
hitratio = hits.sum().to_frame().unstack().T.droplevel(0)
hitratio /= VaRret.dropna().shape[0]
hitratio.plot.bar();
plt.axhline(QUANTILE,color='k')
plt.title('Hit Ratio')
plt.show()
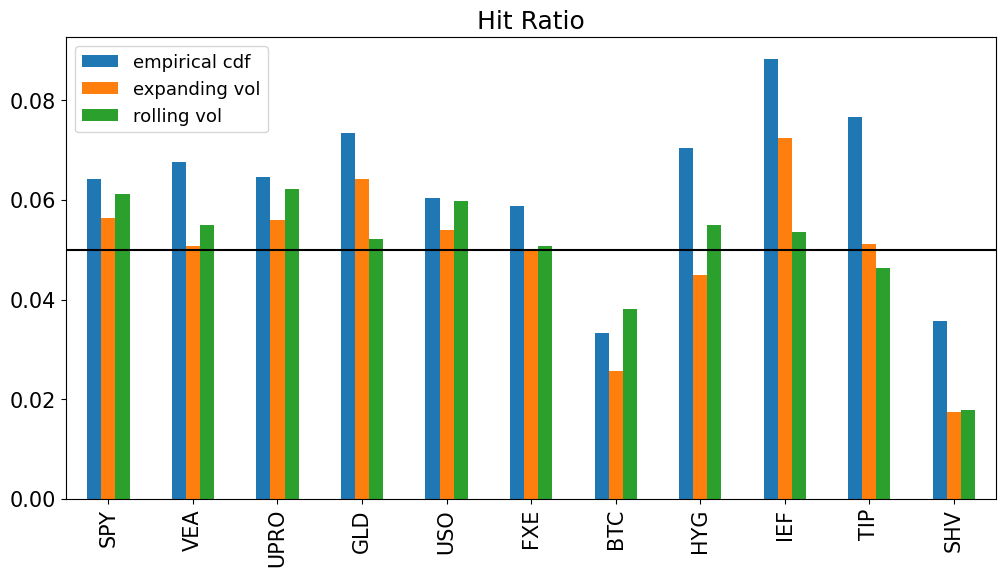
sum_sq_errors = ((hitratio-QUANTILE)**2).sum().to_frame('hit ratio errors')
sum_sq_errors.style.format('{:.2%}')
| hit ratio errors | |
|---|---|
| empirical cdf | 0.45% |
| expanding vol | 0.25% |
| rolling vol | 0.16% |
tick = 'GLD'
fig, ax = plt.subplots(len(METHODS),1,figsize=(12,15))
for i,method in enumerate(METHODS):
VaRret[method][tick].plot(ax=ax[i],title=f'{tick} VaR {method}')
for xval in rets.index[hits.swaplevel(axis=1)[tick][method]]:
ax[i].axvline(x=xval,color='lightgray', zorder=0)
plt.tight_layout()
plt.show()
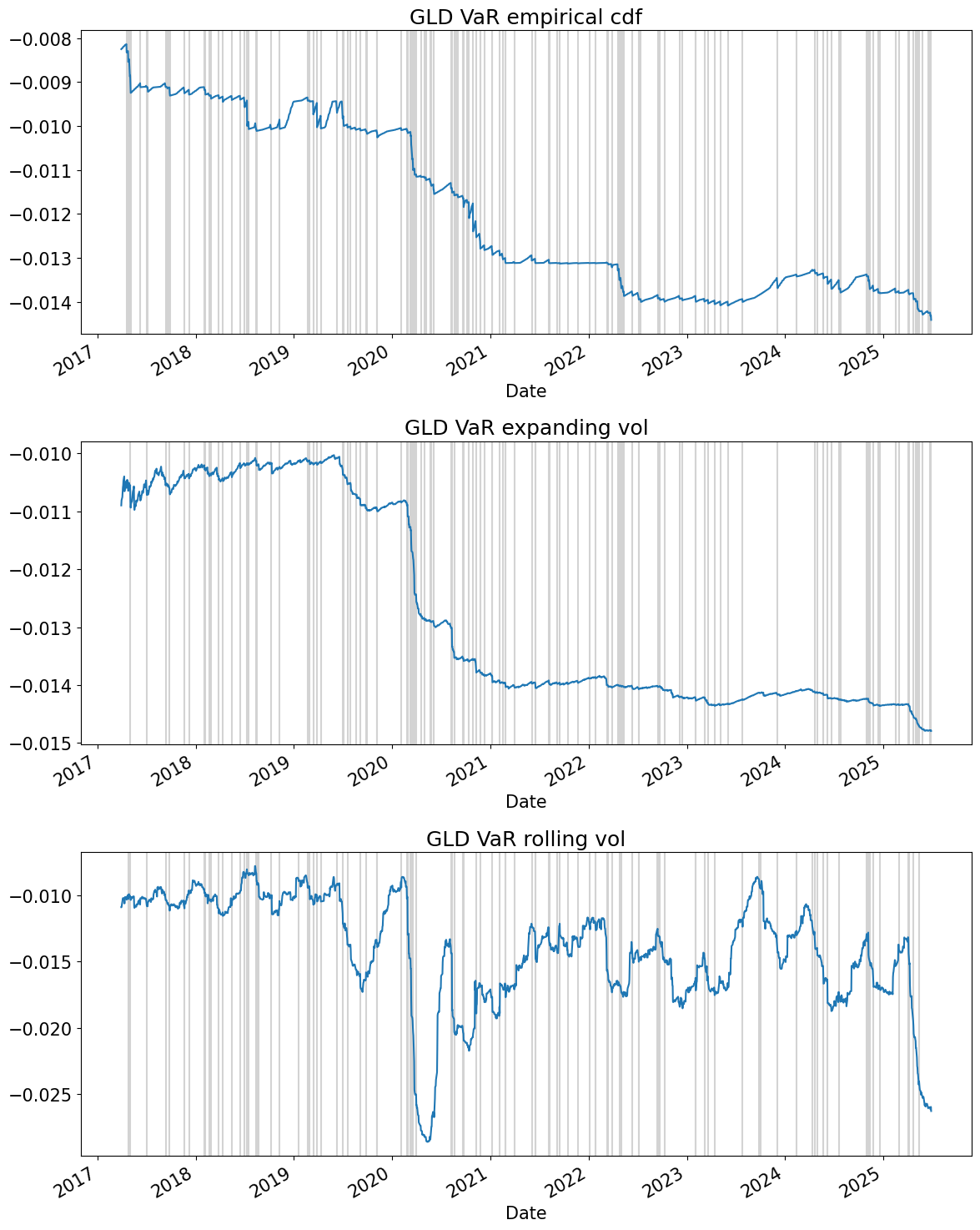
Simulation#
Historic Simulation (Empirical CDF)#
Historical simulation is one of the simplest and most widely used approaches to calculating VaR.
The historical simulation does not assume normally distributed losses.
However, it is an unconditional VaR, in that it assumes independent observations.
It takes the cdf of losses from the histogram of past losses.
Calculate the \(\VaR\) as the empirical quantile, exactly as discussed earlier.
CVaR#
Obtain the \(\CVaR\) again using the order statistics to build the cdf:
This is just the sample mean of the left tail of the empirical cdf.
Advantages of Historical Simulation#
Advantages of historical simulation This approach estimates a cdf of losses nonparametrically by assuming the subsample frequency reflects the actual probabilities.
Thus, the estimated cdf can have any shape, based on the historic observations.
The two main advantages here are the ease of implementation and the flexibility in not assuming a probability distribution, (such as the normal,) ex-ante.
Disadvantages of Historical Simulation#
Statistical Power#
The VaR depends on having a good estimate of the tail of the distribution.
If the sample size, N, is small, then there will be large standard errors on the order statistic. (The standard errors shrink by the square root of the sample size.)
If stress-testing extreme market conditions, need a sample of 10,000 just to get 10 observations in the 0.1% tail of the distribution.
Dynamics#
The approach assumes returns are iid, which they are not.
Take too big of a sample, and may be including irrelevant data, data which came from different distribution compared to data going forward.
But too small a sample, and no precision.
Monte Carlo Simulation#
Monte Carlo simulation generates data according to some statistical model.
Use each simulated observation to construct the corresponding portfolio loss.
Build an empirical cdf (histogram) from these simulated losses, and select the appropriate quantile.
MC has many applications:
Historical approach simply skips the first step by taking observed past as the generated data.
By using simulated cdf no need to worry about keeping the cdf tractable. Important for complicated dynamics or nonlinear valuation.
Simulating Bonds and Options#
Monte Carlo simulation is usefully applied to cases where the portfolio value is nonlinear in the simulated factors.
Consider simulating stock prices and then plugging the simulated data into Black-Scholes to obtain simulated losses on options.
Simulate interest rates and then calculate bond portfolio losses as nonlinear function of these simulated data.
Other Approaches#
\(t\)-distribution#
The normal distribution was not good enough, so why not try other known distributions?
This is indeed done, most notably with the Student’s \(t\) distribution.
Fatter tails than a normal, so will do better.
But in some senses, it is a half-measure: computational work that is less useful for quoting and baseline, yet not enough computational work to be as serious as we would like.
Extreme Value Theory#
Other distributions do not fit the center of the return data well.
Thus, Extreme Value Theory seeks distributions only for the extreme values of the distribution.
Uses mathematical results to model just the tail.
Quantile Regression#
Empically try to estimate the quantiles using some conditioning information, rather than the direct approach discussed above.