Optimization via Regression#
import pandas as pd
import numpy as np
import datetime
import warnings
pd.options.display.float_format = "{:,.4f}".format
import matplotlib.pyplot as plt
%matplotlib inline
plt.rcParams['figure.figsize'] = (12,6)
plt.rcParams['font.size'] = 15
plt.rcParams['legend.fontsize'] = 13
from matplotlib.ticker import (MultipleLocator,
FormatStrFormatter,
AutoMinorLocator)
from sklearn.linear_model import LinearRegression
from sklearn.decomposition import PCA
from scipy.optimize import minimize
import seaborn as sns
import statsmodels.api as sm
from sklearn.linear_model import Lasso, Ridge
from sklearn.decomposition import PCA
from cmds.portfolio import *
Import and Organize Data#
DATAFILE = '../data/risk_etf_data.xlsx'
FREQ = 252
TICKER_CASH = 'SHV'
DROP_CASH = True
info = pd.read_excel(DATAFILE,sheet_name='descriptions')
#info.rename(columns={'Unnamed: 0':'Symbol'},inplace=True)
info.set_index('ticker',inplace=True)
rets = pd.read_excel(DATAFILE,sheet_name='total returns')
rets.set_index('Date',inplace=True)
if DROP_CASH:
rets.drop(columns=['SHV'],inplace=True)
TICKS_DROP = ['BTC','UPRO']
rets.drop(columns=TICKS_DROP,inplace=True)
# retsx = rets.subtract(rets['SHV'],axis=0)
retsx = rets.copy()
# retsx.drop(columns=['SHV'],inplace=True)
Ntime, Nassets = retsx.shape
print(f'Number of assets: {Nassets:.0f}')
print(f'Number of periods: {Ntime:.0f}')
display(retsx.head().style.format('{:.1%}'.format).format_index('{:%Y-%m-%d}'))
display_correlation(retsx)
Number of assets: 8
Number of periods: 2132
| SPY | VEA | GLD | USO | FXE | HYG | IEF | TIP | |
|---|---|---|---|---|---|---|---|---|
| Date | ||||||||
| 2017-01-04 | 0.6% | 1.2% | 0.4% | 1.2% | 0.9% | 0.5% | 0.1% | 0.2% |
| 2017-01-05 | -0.1% | 0.9% | 1.6% | 1.0% | 1.1% | -0.1% | 0.6% | 0.3% |
| 2017-01-06 | 0.4% | -0.4% | -0.7% | -0.2% | -0.7% | -0.0% | -0.5% | -0.4% |
| 2017-01-09 | -0.3% | -0.2% | 0.8% | -3.2% | 0.4% | -0.0% | 0.4% | 0.2% |
| 2017-01-10 | 0.0% | 0.1% | 0.4% | -2.1% | -0.1% | 0.0% | -0.0% | 0.1% |
MIN Correlation pair is ('IEF', 'USO')
MAX Correlation pair is ('SPY', 'VEA')
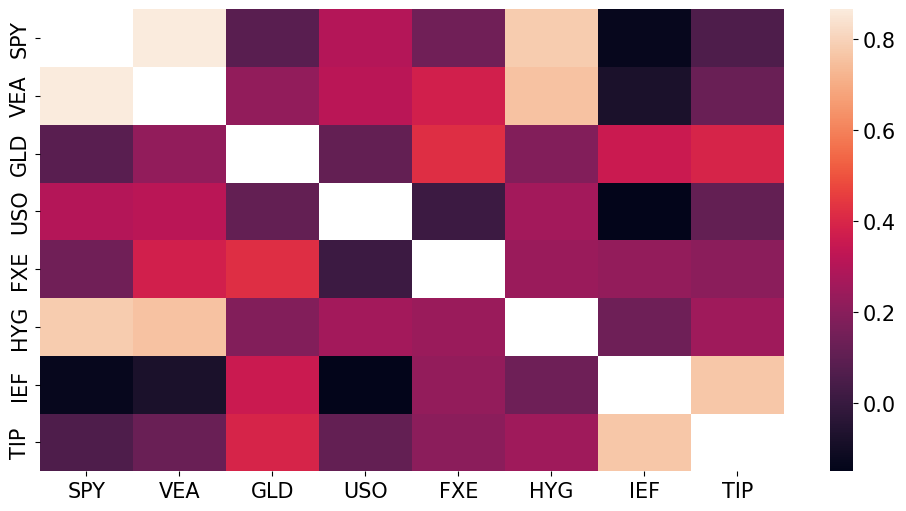
Figure of Mean-Variance Optimization#
import os
import sys
if os.path.isfile('../dev/extras.py'):
sys.path.insert(0, '../dev')
from extras import MVweights, plotMV
figrets = rets
label = 'GMV'
wstar = pd.DataFrame(MVweights(figrets,target=label),index=figrets.columns,columns=[label])
label = 'TAN'
wstar[label] = MVweights(figrets,target=label,isexcess=False)
wts_a = wstar['TAN']
wts_b = wstar['GMV']
fig = plotMV(wts_a,wts_b,figrets.mean(),figrets.cov(),labels=['TAN','GMV'],annualize=12)
Description of Individual Asset Sharpe Ratios#
(retsx.mean()/retsx.std()).to_frame().describe().rename({0:'Sharpe Ratio Summary'},axis=1).drop(index=['count']).style.format('{:.2%}'.format)
| Sharpe Ratio Summary | |
|---|---|
| mean | 2.99% |
| std | 1.81% |
| min | 0.82% |
| 25% | 1.31% |
| 50% | 3.13% |
| 75% | 3.90% |
| max | 5.68% |
Mean-Variance Optimization is OLS#
OLS when Projecting a Constant#
The OLS estimator of regressing \(y\) on \(X\) (no intercept) is:
Though it may seem unusual we could regress a constant on regressors:
Obviously, if we included an intercept, the regression would be degenerate with \(\alpha=1, \beta=0, \epsilon_t=0\).
Regress the constant, 1, on returns. So \(X=R\) and \(y=1\).
where
\(\boldsymbol{1}_{T}\) denotes the \(T\times 1\) vector of ones.
The OLS solution as sample moments#
Scaling
The OLS betas will not sum to one, but we can include a scaling factor to ensure this, and we can refer to this as a weight vector,
\(\boldsymbol{w}_{ols}\):
where \(\boldsymbol{1}_{N}\) denotes a \(N\times 1\) vector of ones.
Mean-Variance Solution#
Using sample estimates for the moments above, we have:
where \(\hat{c}_{\text{mv}}\) is a constant that ensures \(\boldsymbol{\hat{w}}_{tan}\) sums to 1.
Equality#
If we go through the tedious linear algebra, we find
Scaling of the constant used as the dependent variable#
We are using the constant \(1\) on the left-hand-side as the dependent variable.
For OLS, the scaling of this constant simply changes the sum of the weights. Thus, it impacts the exact scaling constant, \(\hat{c}_{ols}\), which enforces the weights to sum to 1.
Going beyond MV, the scaling may matter!#
For more complex optimization, the solution weights do not scale proportionally with the target mean, as they do for the excess-return Mean-Variance frontier.
In those cases, we may need to rescale the regressand constant to trace out the frontier.
Conclusion#
Mean Variance Optimization is equivalent to OLS of a constant on the returns.
This means…
We can get statistical significance of the MV weights.
We can restrict the MV solution in ways we commonly restrict OLS. This includes Non-Negative Least Squares.
We can restrict the number of positions in the MV solution. (LASSO).
We can restrict the position sizes in the MV solution via a penalty parameter instead of \(2n\) boundary constraints. (Ridge).
wts = tangency_weights(retsx).rename({'tangency weights':'MV'},axis=1)
# for OLS, doesn't matter what scaling we give y, just use y=1
# but note that below this scaling may matter
y = np.ones((Ntime,1))
X = retsx
beta = LinearRegression(fit_intercept=False).fit(X,y).coef_.transpose()
# rescale OLS beta to sum to 1
beta /= beta.sum()
wts['OLS'] = beta
wts.style.format('{:.2%}'.format)
| MV | OLS | |
|---|---|---|
| SPY | 112.16% | 112.16% |
| VEA | -68.37% | -68.37% |
| GLD | 77.11% | 77.11% |
| USO | -6.51% | -6.51% |
| FXE | 0.12% | 0.12% |
| HYG | -43.66% | -43.66% |
| IEF | -56.54% | -56.54% |
| TIP | 85.69% | 85.69% |
Confirmation#
They are the same weights!
So we drop the redundant
OLScolumn.
Statistical Significance (in-sample) of these weights#
Get them from the usual OLS t-stats!
tstats = pd.DataFrame(sm.OLS(y, X).fit().tvalues,columns=['t-stat'])
display(tstats.loc[tstats['t-stat'].abs()>2].sort_values('t-stat',ascending=False).style.format('{:.2f}'.format))
| t-stat | |
|---|---|
| GLD | 2.46 |
| SPY | 2.34 |
No Short Positions#
Implement via Non-Negative Least Squares (NNLS)
Do this instead of using Constrained Optimization with \(k\) boundary constraints.
NNLS is doing the Linear Programming with inequalities the same as we would do with Constrained Optimization, but it saves us some work in implementation.
# for NLLS, scaling of y does not matter
y = np.ones((Ntime,1))
X = retsx
beta = LinearRegression(fit_intercept=False, positive=True).fit(X,y).coef_.transpose()
beta /= beta.sum()
beta
wts['NNLS'] = beta
wts.loc[wts['NNLS']>0, ['NNLS']].sort_values('NNLS',ascending=False).style.format('{:.2%}'.format)
| NNLS | |
|---|---|
| GLD | 49.89% |
| SPY | 34.84% |
| TIP | 15.28% |
Regularized Regressions are Useful#
The OLS interpretation of MV makes clear that due to multicolinearity, the optimal in-sample weights can be extreme.
Instead, we may want to use regularized regression to deal with the following constraints.
Constraints
restrict gross leverage, \(\sum_{i}^n |w^i| \le L\)
limit the total number of positions, \(\sum_{i}^n\mathbb{1}_{\ne0}\left(w^i\right) \le K\)
where \(\mathbb{1}_{\ne0}\left(w^i\right)\) denotes the indicator function, equal to 1 if \(w^i\ne 0\) and equal to 0 if \(w^i=0\).
This can be done somewhat clumsily with the traditional constrained optimization.
But other challenges are hard to address with traditional techniques
Challenges
Limit positions from being too large, without specifying security-specific boundaries.
Put more emphasis on out-of-sample performance
Implement a Bayesian approach to Mean-Variance optimization
Ridge Estimation#
Ridge estimation may help with the challenges above.
Except it will NOT limit the total number of positions.
The Ridge estimator is the optimized solution for a regularized regression with an L2 penalty.
Recall that the Ridge estimator is
where
\(\mathcal{I}_n\) is the \(n\times n\) identity matrix.
\(\lambda\) is a hyperparameter (“tuning” parameter) related to the L2 penalty.
Note that this is the exact same as OLS, except we have a modified second-moment matrix. In our application of regressing 1 on returns without an intercept, the point is that instead of the OLS calculation,
we use
For \(\lambda=0\), we simply have OLS.
For large \(\lambda\), we are diagonalizing the second-moment matrix. (Since we do not regress on an intercept, this is the uncentered second-moment matrix, not quite the covariance matrix.)
Conclusion#
The Ridge estimator is diagonalizing the second-moment matrix, which makes it more stable for inversion.
This reduces its sensitivity to small changes in the data, and allows it to perform more consistently out-of-sample, though less optimally in-sample.
Conceptually, this means that it constructs less extreme long-short weights given that it diminishes the magnitudes of the correlations relative to the main diagonal.
Statistically, the extra term on the second-moment matrix is reducing the impact the multicolinearity of the asset returns have on the estimate.
LASSO Estimation#
LASSO estimation helps with the challenges above.
Additionally, LASSO can reduce the number of positions, (dimension reduction.)
Unlike Ridge, there is no closed-form solution for the LASSO estimator.
Bayesian Interpretation#
Ridge
The Ridge estimator is a Bayesian posterior assuming a Normally distributed prior on the betas, updated via normally distributed sample data.
LASSO
The LASSO estimator is a Bayesian posterior assuming a Laplace-distributed prior on the betas, updated via normally distributed sample data.
This does not mean Ridge requires us to believe the data is normally distributed. That is an assumption to interpret it as thte Bayesian solution.
def penalized_reg_limit_gross(func, X, y, limit=2, penalty=1e-6, fit_intercept=True):
wts = np.ones(X.shape[1]) * 100
while np.abs(wts).sum()>limit:
penalty *= 1.25
model = func(alpha=penalty, fit_intercept=fit_intercept).fit(X,y)
wts = model.coef_ / model.coef_.sum()
return wts, penalty
GROSS_LIMIT = 2
if wts['MV'].abs().sum()<2:
GROSS_LIMIT = 1.25
# scaling of y will impact the solution if penalty held constant
# here, we adjust the penalty to ensure the scaling, so initial scaling of y is less important
betas, penalty_ridge = penalized_reg_limit_gross(Ridge, retsx, y, limit=GROSS_LIMIT, fit_intercept=False)
wts['Ridge'] = betas.transpose()
betas, penalty_lasso = penalized_reg_limit_gross(Lasso, retsx, y, limit=GROSS_LIMIT, fit_intercept=False)
wts['Lasso'] = betas.transpose()
print(f'Penalty for Ridge: {penalty_ridge : .2e}.\nPenalty for LASSO: {penalty_lasso : .2e}.')
Penalty for Ridge: 4.48e-02.
Penalty for LASSO: 3.55e-05.
Diagonalization and Shrinkage#
Diagonalization#
Diagonalize the covariance matrix (set all off-diagonal terms to 0).
This was popular long before Ridge and continues to be.
Shrinkage Estimators#
“Shrink” the covariance matrix going into MV estimation by mixing a diagonalized version of the matrix with the full matrix, according to some mixing parameter.
The mixing parameter may change over time, depending on the data.
This is equivalent to Ridge for certain specification of the mixing parameter.
So Ridge is another lense for a popular approach to MV optimization.
covDiag = np.diag(np.diag(retsx.cov()))
temp = np.linalg.solve(covDiag,retsx.mean())
wts['Diagonal'] = temp / temp.sum()
Performance#
if 'Equal' not in wts.columns:
wts.insert(0,'Equal',np.ones_like(Nassets)/Nassets)
if 'OLS' in wts.columns:
wts.drop(columns=['OLS'],inplace=True)
retsx_ports = retsx @ wts
display(performanceMetrics(retsx_ports, annualization=FREQ).style.format('{:.2%}'.format))
display(tailMetrics(retsx_ports))
display(get_ols_metrics(retsx['SPY'], retsx_ports,annualization=FREQ).style.format('{:.2%}'.format))
| Mean | Vol | Sharpe | Min | Max | |
|---|---|---|---|---|---|
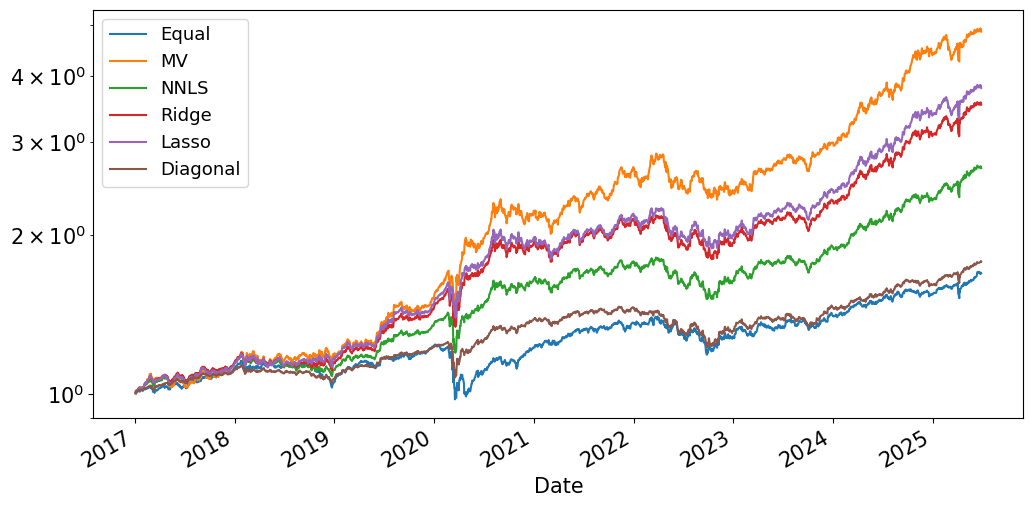
| Equal | 6.64% | 9.27% | 71.71% | -5.66% | 3.85% |
| MV | 19.75% | 14.67% | 134.60% | -4.88% | 8.28% |
| NNLS | 12.17% | 10.42% | 116.80% | -5.36% | 5.59% |
| Ridge | 15.66% | 12.36% | 126.70% | -5.78% | 7.05% |
| Lasso | 16.58% | 12.86% | 128.99% | -5.10% | 7.31% |
| Diagonal | 7.08% | 7.42% | 95.47% | -3.95% | 3.70% |
| Skewness | Kurtosis | VaR (0.05) | CVaR (0.05) | Max Drawdown | Peak | Bottom | Recover | Duration (to Recover) | |
|---|---|---|---|---|---|---|---|---|---|
| Equal | -1.1206 | 14.0213 | -0.0080 | -0.0136 | -0.2129 | 2020-01-06 | 2020-03-18 | 2021-01-20 | 380 days |
| MV | 0.1777 | 6.4869 | -0.0136 | -0.0210 | -0.1823 | 2022-03-25 | 2022-11-03 | 2023-10-19 | 573 days |
| NNLS | -0.0547 | 9.8414 | -0.0098 | -0.0149 | -0.1661 | 2022-03-24 | 2022-09-27 | 2023-07-18 | 481 days |
| Ridge | 0.1883 | 9.7861 | -0.0115 | -0.0177 | -0.1746 | 2022-03-24 | 2022-10-14 | 2023-07-17 | 480 days |
| Lasso | 0.2004 | 8.2167 | -0.0122 | -0.0184 | -0.1616 | 2022-04-13 | 2022-10-14 | 2023-07-11 | 454 days |
| Diagonal | -0.3391 | 11.5589 | -0.0066 | -0.0106 | -0.1620 | 2021-11-09 | 2022-09-27 | 2023-12-26 | 777 days |
| alpha | SPY | r-squared | Treynor Ratio | Info Ratio | |
|---|---|---|---|---|---|
| Equal | 1.15% | 35.90% | 53.33% | 18.51% | 18.25% |
| MV | 12.57% | 46.91% | 36.33% | 42.10% | 107.40% |
| NNLS | 6.30% | 38.40% | 48.24% | 31.70% | 84.03% |
| Ridge | 8.68% | 45.64% | 48.44% | 34.31% | 97.82% |
| Lasso | 9.66% | 45.28% | 44.06% | 36.63% | 100.46% |
| Diagonal | 2.58% | 29.45% | 56.01% | 24.05% | 52.41% |
(1+retsx_ports).cumprod().plot(logy=True);
retsx_ports.corr().style.format('{:.2%}'.format)
| Equal | MV | NNLS | Ridge | Lasso | Diagonal | |
|---|---|---|---|---|---|---|
| Equal | 100.00% | 53.28% | 80.25% | 68.32% | 63.40% | 88.53% |
| MV | 53.28% | 100.00% | 86.78% | 94.13% | 95.83% | 70.93% |
| NNLS | 80.25% | 86.78% | 100.00% | 97.44% | 94.18% | 94.10% |
| Ridge | 68.32% | 94.13% | 97.44% | 100.00% | 98.67% | 87.21% |
| Lasso | 63.40% | 95.83% | 94.18% | 98.67% | 100.00% | 81.39% |
| Diagonal | 88.53% | 70.93% | 94.10% | 87.21% | 81.39% | 100.00% |
wts.abs().sum().plot.bar(title='Gross Leverage');
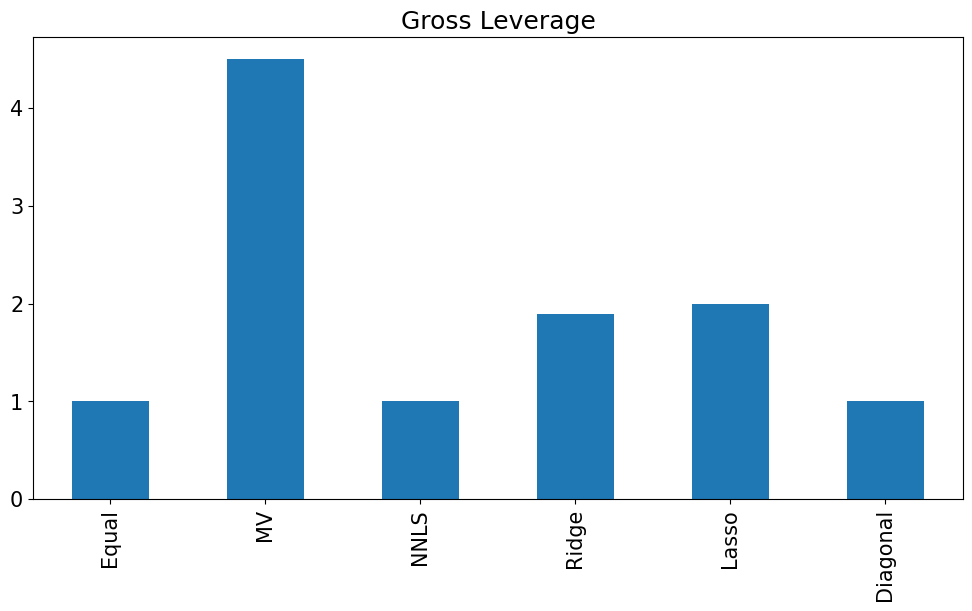
wts.style.format('{:.2%}'.format)
| Equal | MV | NNLS | Ridge | Lasso | Diagonal | |
|---|---|---|---|---|---|---|
| SPY | 12.50% | 112.16% | 34.84% | 62.57% | 79.66% | 12.84% |
| VEA | 12.50% | -68.37% | 0.00% | -19.39% | -45.48% | 9.45% |
| GLD | 12.50% | 77.11% | 49.89% | 64.11% | 70.09% | 18.85% |
| USO | 12.50% | -6.51% | 0.00% | -4.46% | -3.53% | 1.00% |
| FXE | 12.50% | 0.12% | 0.00% | -10.05% | -0.00% | 8.78% |
| HYG | 12.50% | -43.66% | 0.00% | -7.62% | -0.75% | 18.41% |
| IEF | 12.50% | -56.54% | 0.00% | -3.24% | -0.00% | 7.94% |
| TIP | 12.50% | 85.69% | 15.28% | 18.09% | 0.00% | 22.73% |
Performance Out-of-Sample#
%%time
ADJUST_PENALTY = True
GROSS_LIMIT = 2
minT = 12*10
methods = ['SPY','Equal','MV','NNLS', 'Ridge','Lasso']
# initialize
wts_oos = pd.concat([pd.DataFrame(index=rets.index, columns=rets.columns)]*len(methods), keys=methods, axis=1)
equal_wts = np.ones(Nassets) / Nassets
for t in wts_oos.index:
R = retsx.loc[:t,:]
y = np.ones(R.shape[0])
if R.shape[0] >= minT:
wts_oos.loc[t,'Equal',] = equal_wts
if 'SPY' in R.columns:
wts_oos.loc[t,'SPY',] = 0
wts_oos.loc[t,('SPY','SPY')] = 1
wts_oos.loc[t,'MV',] = LinearRegression(fit_intercept=False).fit(R,y).coef_
wts_oos.loc[t,'NNLS',] = LinearRegression(positive=True, fit_intercept=False).fit(R,y).coef_
wts_oos.loc[t,'Ridge',] = Ridge(alpha= penalty_ridge, fit_intercept=False).fit(R,y).coef_
wts_oos.loc[t,'Lasso',] = Lasso(alpha= penalty_lasso, fit_intercept=False).fit(R,y).coef_
# dynamically adjust the penalty parameter
# takes longer to run, brings gross leverage down
if ADJUST_PENALTY:
betas, penalty_ridge = penalized_reg_limit_gross(Ridge, R, y, limit=GROSS_LIMIT, fit_intercept=False)
betas, penalty_lasso = penalized_reg_limit_gross(Lasso, R, y, limit=GROSS_LIMIT, fit_intercept=False)
for method in methods:
div_factor = wts_oos[method].sum(axis=1)
div_factor[div_factor==0] = 1
wts_oos[method] = wts_oos[method].div(div_factor, axis='rows')
wts_oos_lag = wts_oos.shift(1)
retsx_port_oos = pd.DataFrame(index=retsx.index, columns = methods)
for method in methods:
retsx_port_oos[method] = (wts_oos_lag[method] * retsx).sum(axis=1)
# do not count burn-in period
retsx_port_oos.iloc[:minT,:] = None
display(performanceMetrics(retsx_port_oos, annualization=12).style.format('{:.2%}'.format))
display(tailMetrics(retsx_port_oos))
display(get_ols_metrics(retsx['SPY'], retsx_port_oos,annualization=12).style.format('{:.2%}'.format))
wts_all = wts_oos.unstack().groupby(level=(0,2))
wts_all_diff = wts_oos.diff().unstack().groupby(level=(0,2))
gross_leverage = wts_all.apply(lambda x: sum(abs(x))).unstack(level=0)
turnover = wts_all_diff.apply(lambda x: sum(abs(x))).unstack(level=0)
num_positions = wts_all.apply(lambda x: sum(abs(x)>0)).unstack(level=0)
max_wt = wts_all.apply(lambda x: max(x)).unstack(level=0)
min_wt = wts_all.apply(lambda x: min(x)).unstack(level=0)
dates_active = (rets.index[minT],rets.index[-1])
display(retsx_port_oos.corr().style.format('{:.2%}'.format))
gross_leverage.mean().plot.bar(title='Gross Leverage');
gross_leverage.plot(title='Gross Leverage',xlim=dates_active)
turnover.rolling(12*1).mean().plot(title='Turnover',xlim=dates_active)
plt.show()
num_positions.plot(title='Number of Positions',xlim=dates_active)
max_wt.plot(title='Max Weight',xlim=dates_active)
plt.show()
min_wt.plot(title='Min Weight',xlim=dates_active)
plt.show()